

Since some time everybody (read developer) want to run his new microservice stacks in containers. I can understand that building and testing an application is important for developers.
One of the benefits of containers is, that developer (in theory) can put their new version of applications into production on their own. This is the point where operations is affected and operations needs to evaluate, if that might evolve into better workflow.
For yolo^WdevOps people there are some challenges that needs to be solved, or at least mitigated, when things needs to be done in large(r) scale.
- Which Orchestration Engine should be considered?
- How to provide persistent (shared) storage?
- How to update the base image(s) the apps are build upon and to test/deploy them?
Orchestration Engine
Running Docker, which is actual the most preferred container solution, on a single host with docker command line client is something you can do, but there you leave the gap between dev and ops.
UI For Docker
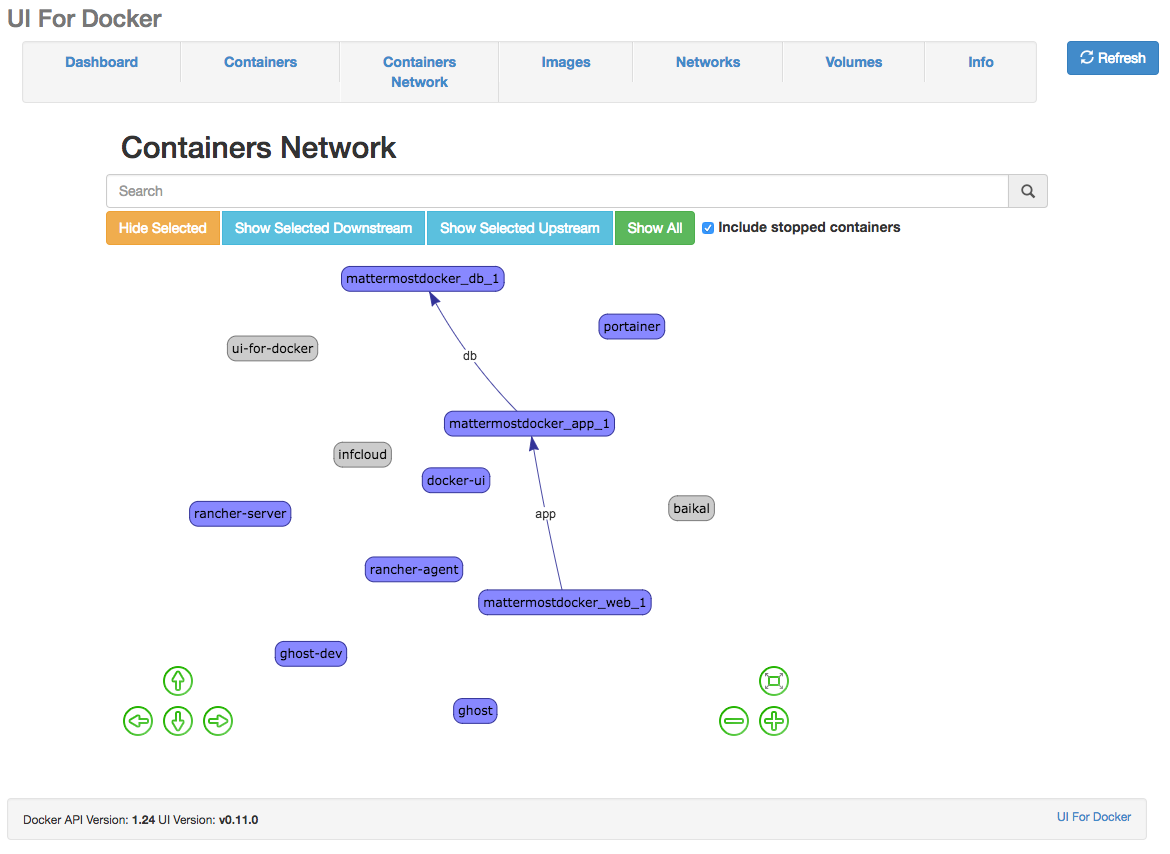
Since some time there is UI For Docker available for visualizing and managing containers on a single docker node. It's pretty awesome and the best feature so far is the Container Network view, which also shows the linked container.
Portainer
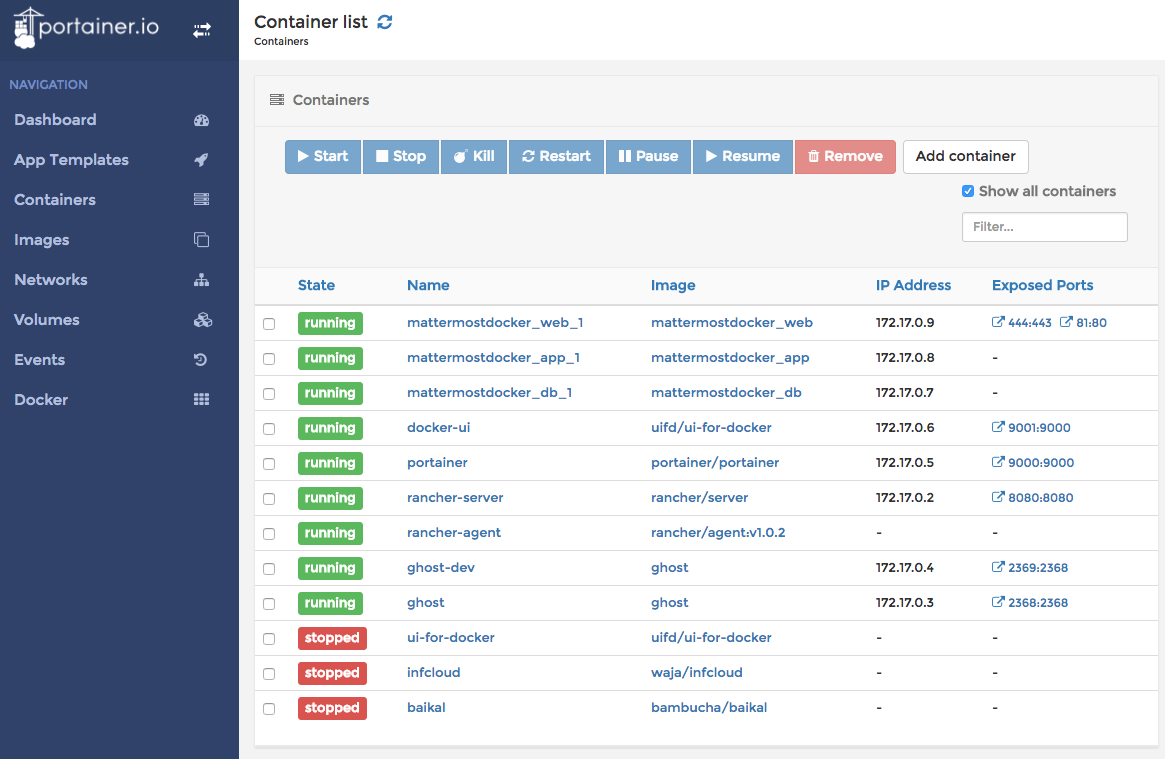
Portainer is pretty new and it can be deployed as easy as UI For Docker. But the (first) great advantage: it can handle Docker Swarm. Beside that it has many other great features.
Rancher
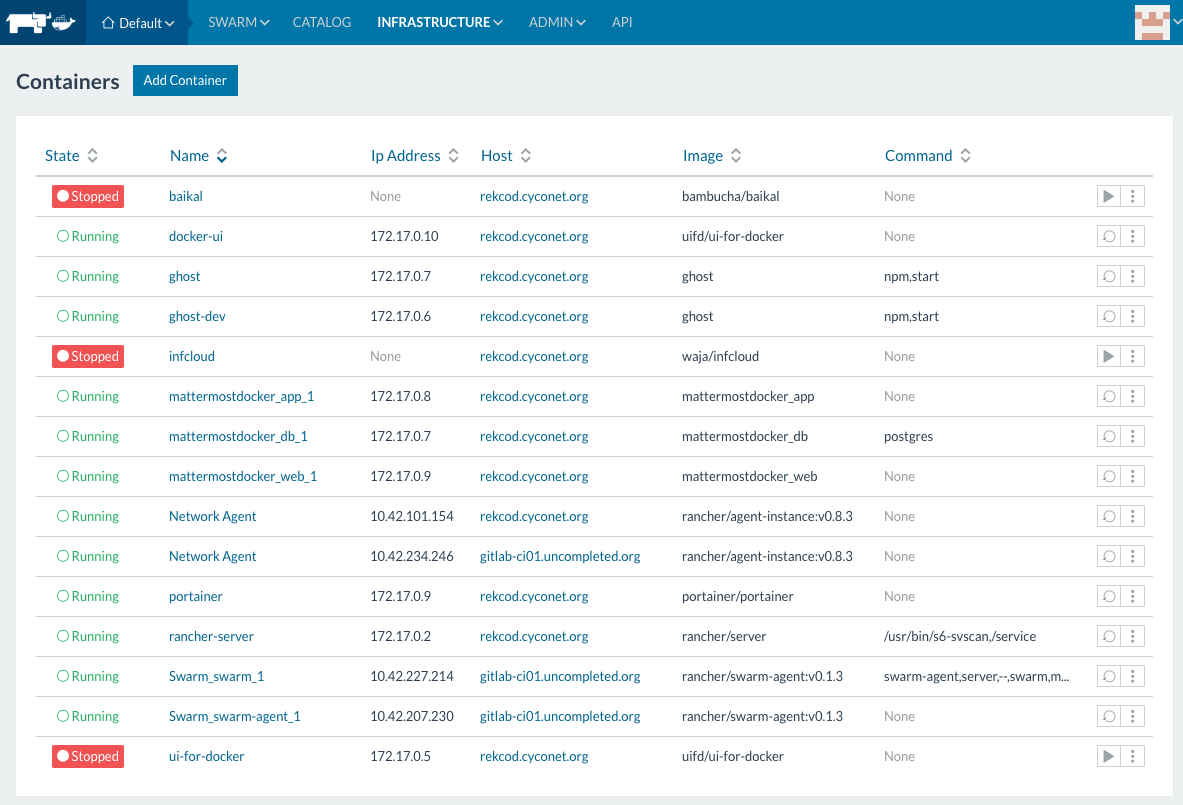
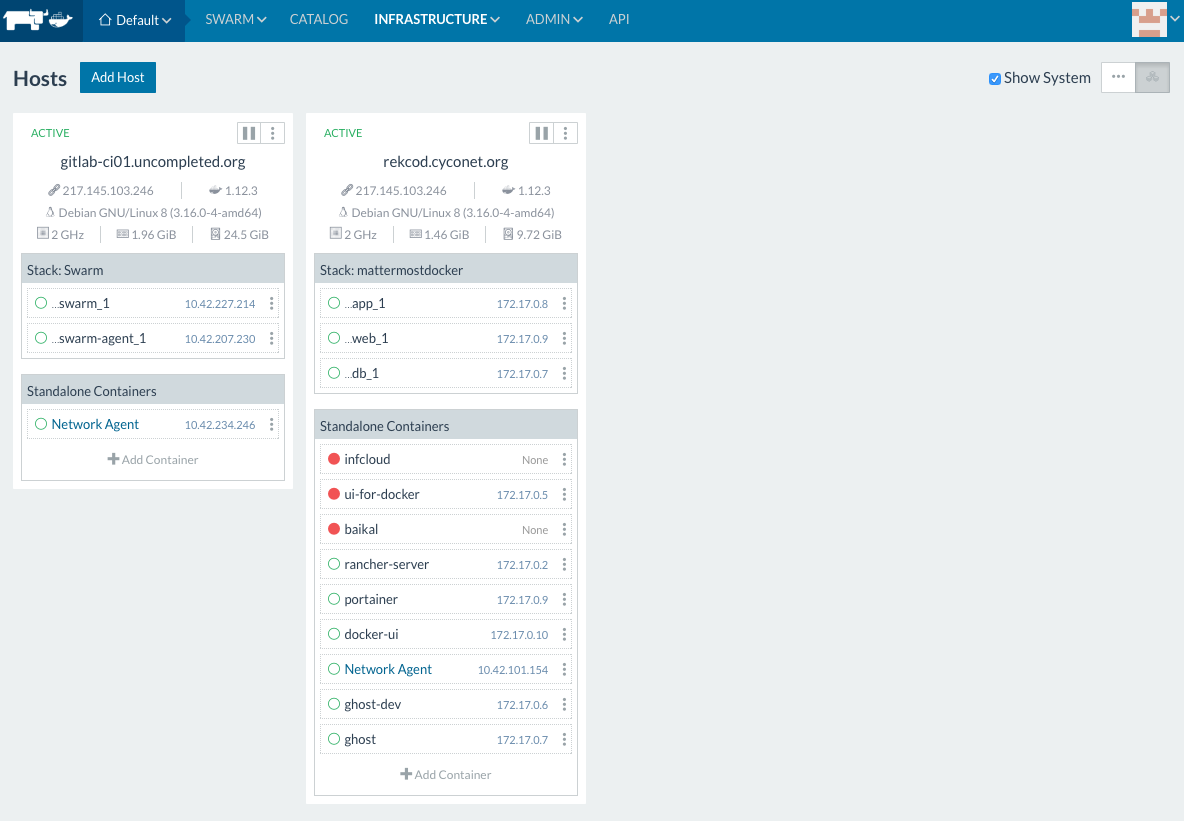
Rancher describes themselves as 'container management platform' that 'supports and manages all of your Kubernetes, Mesos, and Swarm clusters'. This is great because this are all of the relevant docker cluster orchestrations at the market actually.
For the use cases, we are facing, Kubernetes and Mesos seems both like bloated beasts. Usman Ismail has written a really good comparison of Orchestration Engine options which goes into details.
Docker Swarm
As there is actually no clear defacto standard/winner of the (container) orchestration wars, I would prevent to be in a vendor lock-in situation (yet). Docker swarm seems to be evolving and is getting more nice features other competitors doesn't provide.
Due the native integration into the docker framework and great community I believe Docker Swarm will be the Docker Orchestration of the choice on the long run. This should be supported by Rancher 1.2 which is not released yet.
From this point of view it looks very reasonable that Docker Swarm in combination with Rancher (1.2) might be a good strategy to maintain your container farms in the future.
If you think to put Docker Swarm into production in the actual state, I recommend to read Docker swarm mode: What to know before going live on production by Panjamapong Sermsawatsri.
Persistent Storage
While it is a best practice to use data volume container these days, providing persistent storage across multiple hosts for shared volumes seems to be tricky.
In theory you can mount a shared-storage volume as a data volume and there are several volume plugins which supports shared storage.
For example you can use the convoy plugin which gives you:
- thin provisioned volumes
- snapshots of volumes
- backup of snapshots
- restore volumes
As backend you can use:
- Device Mapper
- Virtual File System(VFS)/Network File System(NFS)
- Amazon Elastic Block Store(EBS)
The good thing is, that convoy is integrated into Rancher. For more information I suggest to read Setting Up Shared Volumes with Convoy-NFS, which also mentions some limitations. If you want test Persistent Storage Service, Rancher provides some documentation.
Actually I did not evaluate shared-storage volumes yet, but I don't see a solution I would love to use in production (at least on-premise) without strong downsides. But maybe things will go further and there might be a great solution for this caveats in the future.
Keeping base images up-to-date
Since some time there are many projects that tries to detect security problems in your container images in several ways.
Beside general security considerations you need to deal somehow with issues in your base images that you build your applications on.
Of course, even if you know you have a security issue in your application image, you need to fix it, which depends on the way how you based your application upon.
Ways to base your application image
- You can build your application image entire from scratch, which leaves all the work to your development team and I wouldn't recommend it that way.
- You also can create one (or more) intermediate image(s) that will be used by your development team.
- The development team might ground their work on images in public available or private (for example the one bundled to your gitlab CI/CD solution) registries.
Whats the struggle with the base image?
If you are using images being not (well) maintained by other people, you have to wait for them to fix your base image. Using external images might also lead into trust problems (can you trust those people in general?).
In an ideal world, your developers have always fresh base images with fixed security issues. This can probably be done by rebuilding every intermediate image periodically or when the base image changes.
Paradigm change
Anyway, if you have a new application image available (with no known security issues), you need to deploy it to production. This is summarized by Jason McKay in his article Docker Security: How to Monitor and Patch Containers in the Cloud:
To implement a patch, update the base image and then rebuild the application image. This will require systems and development teams to work closely together.
So patching security issues in the container world changes workflow significant. In the old world operation teams mostly rolled security fixes for the base systems independent from development teams.
Now hitting containers the production area this might change things significant.
Bringing updated images to production
Imagine your development team doesn't work steady on a project, cause the product owner consider it feature complete. The base image is provided (in some way) consistently without security issues. The application image is build on top of that automatically on every update of the base image.
How do you push in such a scenario the security fixes to production?
From my point of view you have two choices:
- Let the development team require to test the resulting application image and put it into production
- Push the new application image without review by the development team into production
The first scenario might lead into a significant delay until the fixes hit production created by the probably infrequent work of the development team.
The latter one brings your security fixes early to production by the notable higher risk to break your application. This risk can be reduced by implementing massive tests into CI/CD pipelines by the development team. Rolling updates provided by Docker Swarm might also reduce the risk of ending with a broken application.
When you are implementing an update process of your (application) images to production, you should consider Watchtower that provides Automatic Updates for Docker Containers.
Conclusion
Not being a product owner or the operations part of an application that is facing a widely adopted usage that would compensate the actual tradeoffs we are still facing I tend not to move large scale production projects into a container environment.
This means not that this might be a bad idea for others, but I'd like to sort out some of the caveats before.
I'm still interested to put smaller projects into production, being not scared to reimplement or move them on a new stack.
For smaller projects with a small number of hosts Portainer looks not bad as well as Rancher with the Cattle orchestration engine if you just want to manage a couple of nodes.
Things are going to be interesting if Rancher 1.2 supports Docker swarm cluster out of the box. Let's see what the future will bring us to the container world and how to make a great stack out of it.
Update
I suggest to read Docker in Production: A History of Failure and the answer Docker in Production: A retort to understand the actual challenges when running Docker in larger scale production environments.